Claude Opus 4.7 Launch
On April 17, 2026, Anthropic released its next-generation flagship model, Claude Opus 4.7.

This model shows significant improvements in advanced software engineering compared to Opus 4.6, especially in handling complex tasks. Its high-resolution image processing capability has increased to over three times that of previous Claude models. Additionally, Claude Code has introduced a new /ultrareview code review command that initiates a review session to check code changes line by line.
Users report that they can confidently assign the most challenging coding tasks to Opus 4.7, which can rigorously handle long-running tasks, accurately follow instructions, and self-verify outputs before reporting results.
Starting today, Opus 4.7 is available across all Claude products and APIs, including Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. Pricing remains the same as Opus 4.6: $5 per million tokens for input and $25 per million tokens for output. Developers can access it via the Claude API.
Enhanced Instruction Following and Multimodal Support
In testing, Claude Opus 4.7 has shown outstanding performance in several areas, significantly surpassing Opus 4.6:
-
Instruction Following: Opus 4.7 has improved its adherence to instructions, executing them literally rather than interpreting them loosely or skipping parts.
-
Enhanced Multimodal Support: Opus 4.7 can accept images with a maximum long edge of 2576 pixels (approximately 3.75 million pixels), three times that of previous models. This opens up new possibilities for multimodal applications that rely on fine visual details, such as recognizing dense screenshots or extracting data from complex charts.
-
Practical Work: In financial agent evaluations, Opus 4.7 has proven to be a more effective financial analyst than Opus 4.6, producing more rigorous analyses and professional presentations, and integrating tasks more closely.
-
Memory Capability: Opus 4.7 has improved memory capabilities, allowing it to retain important notes over long, multi-session tasks and use this memory to advance new tasks, reducing the need for prior context.
Early testers have provided positive feedback. Clarence Huang, VP of Technology at Intuit, noted that the model can autonomously identify logical errors during the planning phase and operates much faster than its predecessor. Igor Ostrovsky, CTO of Augment Code, highlighted Opus 4.7’s ability to handle automation processes and long task flows effectively, providing its own judgments rather than merely echoing user input.
Leading in Multiple Evaluations
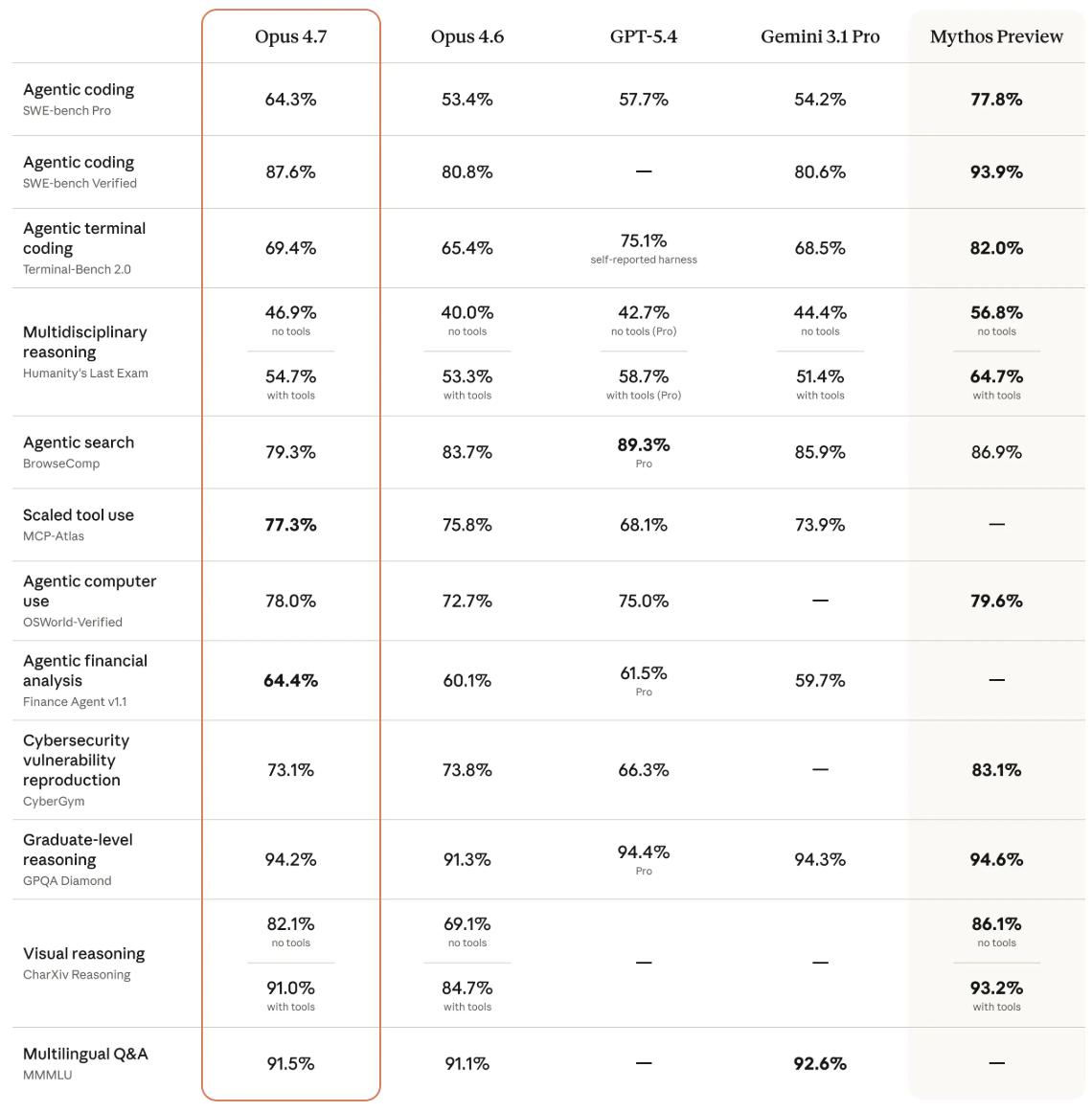
Anthropic conducted pre-release testing of Opus 4.7 across various domains, comparing it with Opus 4.6, GPT-5.4, and Gemini 3.1 Pro.
- Biological Reasoning: Opus 4.7 scored 74.0%, a 1.4x improvement over Opus 4.6’s 30.9%.
- Document Reasoning: Opus 4.7 scored 80.6%, significantly outperforming Opus 4.6’s 57.1%, GPT-5.4’s 51.1%, and Gemini 3.1 Pro’s 42.9%.
- Knowledge Work: Opus 4.7 ranked first with an Elo score of 1753, ahead of GPT-5.4 (1674), Opus 4.6 (1619), and Gemini 3.1 Pro (1314).
- Long Context Reasoning: In simpler parent node lookup tasks, Opus 4.7 scored 75.1% compared to Opus 4.6’s 71.1%. However, in more challenging breadth-first search tasks, Opus 4.7 scored 58.6%, while Opus 4.6 only managed 41.2%, showing a significant improvement in more difficult tasks.
In terms of safety and alignment, Opus 4.7 received a misalignment behavior score of approximately 2.47 (out of 10, with lower being better), slightly better than Opus 4.6’s 2.75 but still trailing behind Mythos Preview’s 1.78. Overall, Opus 4.7 maintains similar safety performance to Opus 4.6, with low rates of deceptive, flattering, and colluding behaviors with abusers.
Additional Updates
In addition to Opus 4.7, Anthropic has launched several feature updates:
- New xhigh Level: An extra-high reasoning level has been added, providing finer adjustments between existing high and max levels. Claude Code’s default reasoning level has been raised to xhigh.
- Task Budget Feature: This feature is now in public beta, allowing developers to guide Claude on token consumption allocation during long tasks.
- New /ultrareview Command: This command initiates a dedicated review session to check code changes line by line, marking bugs and design issues. Pro and Max users receive three free experiences.
Token Usage Considerations
Opus 4.7 is a direct upgrade from Opus 4.6, but two changes affecting token usage are noteworthy:
- Updated Text Processing: Opus 4.7 may consume up to 35% more tokens for the same input compared to its predecessor.
- Higher Reasoning Levels: The model will engage in more thoughtful processing, especially in subsequent rounds of agent scenarios, leading to increased output tokens. Users can manage token usage by adjusting reasoning levels, setting task budgets, or requesting more concise outputs in prompts.
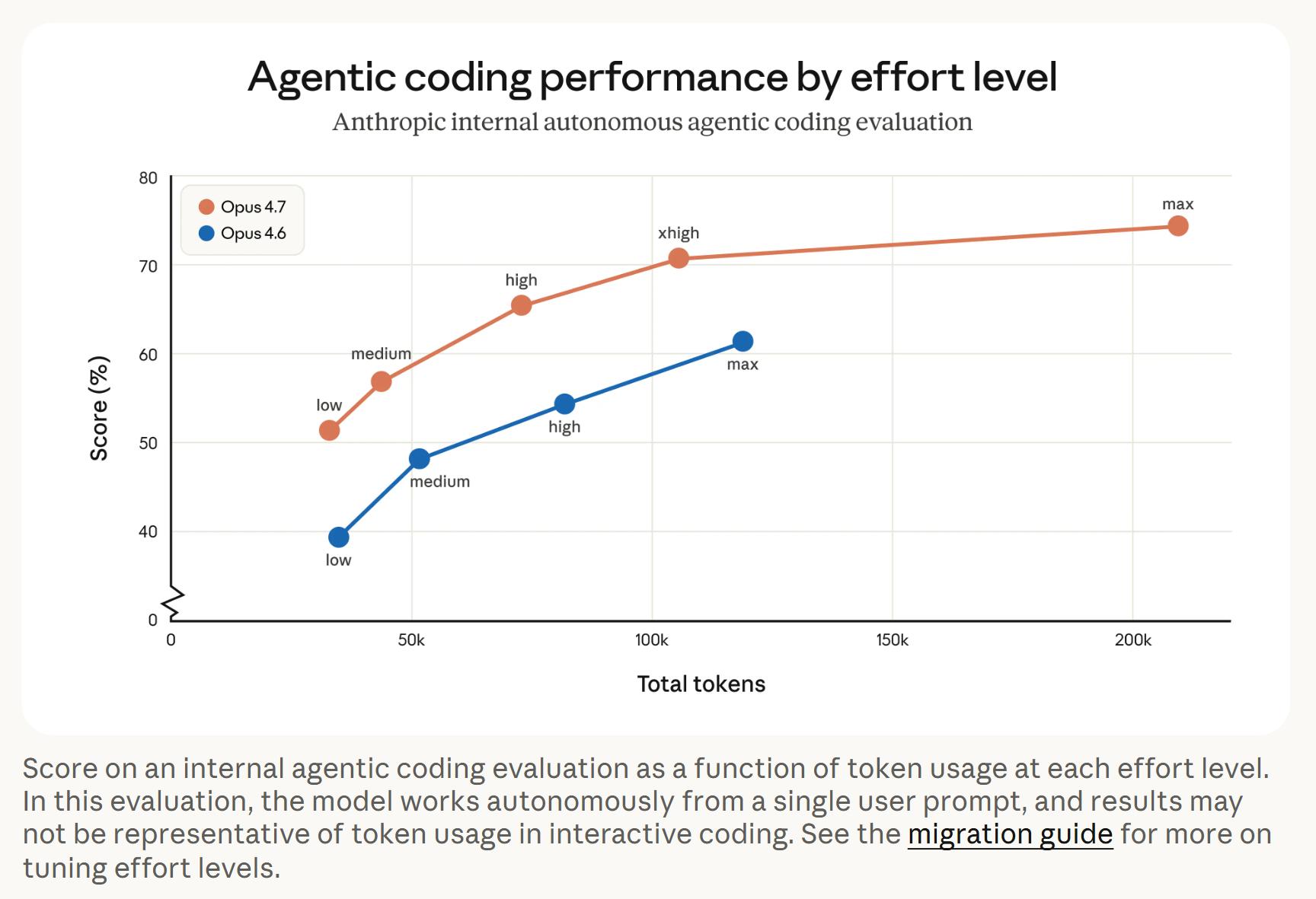
In agent programming evaluations, Opus 4.7 achieved higher scores with fewer tokens across all reasoning levels. For example, it consumed about 100,000 tokens at the xhigh level while scoring over 70%, whereas Opus 4.6 consumed around 130,000 tokens at the max level, just surpassing 60%.
Conclusion
Overall, Opus 4.7 demonstrates significant improvements in programming, document reasoning, biological reasoning, and token efficiency. However, real-world performance still needs further validation. With the release of Opus 4.7, anticipation builds for OpenAI’s next moves and whether the awaited DeepSeek will launch a new model by the end of the month, intensifying competition among large model vendors.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.